Análisis Sintáctico Predictivo Recursivo
Introducción A los Analizadores Sintácticos
Después de la fase de análisis léxico la siguiente fase en la construcción del analizador es la fase de análisis sintáctico. Esta toma como entrada el flujo de terminales y construye como salida el árbol de análisis sintáctico abstracto.
Existen diferentes métodos de análisis sintáctico. La mayoría caen en una de dos categorías:
- ascendentes y
- descendentes.
Los ascendentes construyen el árbol desde las hojas hacia la raíz.
Los descendentes lo hacen en modo inverso.
El que describiremos aquí es un descendente: se denomina método de análisis predictivo descendente recursivo.
Gramáticas Independientes del Contexto
Supongamos una gramática \(G = (\Sigma, V, P, S)\) con alfabeto \(\Sigma\), conjunto de variables sintácticas (o no terminales) \(V\), reglas de producción \(P\) y símbolo de arranque \(S\).
Por ejemplo, en la gramática de Egg este es el conjunto \(P\) de reglas de producción:
expression: STRING
| NUMBER
| WORD apply
apply: /* vacio */
| '(' (expression ',')* expression? ')' apply
Sólo hay dos variables sintácticas \(V = \{ expression, \, apply \}\). El símbolo de arranque \(S\) es \(expression\).
El conjunto de tokens es:
\[\Sigma = \{ STRING,\, NUMBER,\, WORD,\, '(',\, ')',\, ',' \}\]Observe que algunos de los tokens son a su vez lenguajes de cierta complejidad, cuya definición está en otro nivel de abstracción, el nivel léxico y que se pueden definir mediante un mecanismo mas secillo como son las expresiones regulares.
Por ejemplo, en una definición de Egg inicial podríamos definir así lo que entendemos por espacios o blancos, esto es, que partes del texto no son significativas para que nuestro programa pueda entender la estructura de la frase:
WHITES = /(\s|[#;].*|\/\*(.|\n)*?\*\/)*/
así como los tokens mas complejos:
STRING = /"((?:[^"\\]|\\.)*)"/
NUMBER = /([-+]?\d*\.?\d+([eE][-+]?\d+)?)/
WORD = /([^\s(),"]+)/
Clase de PL 2020/04/13: La Gramática de Egg
Ejercicio
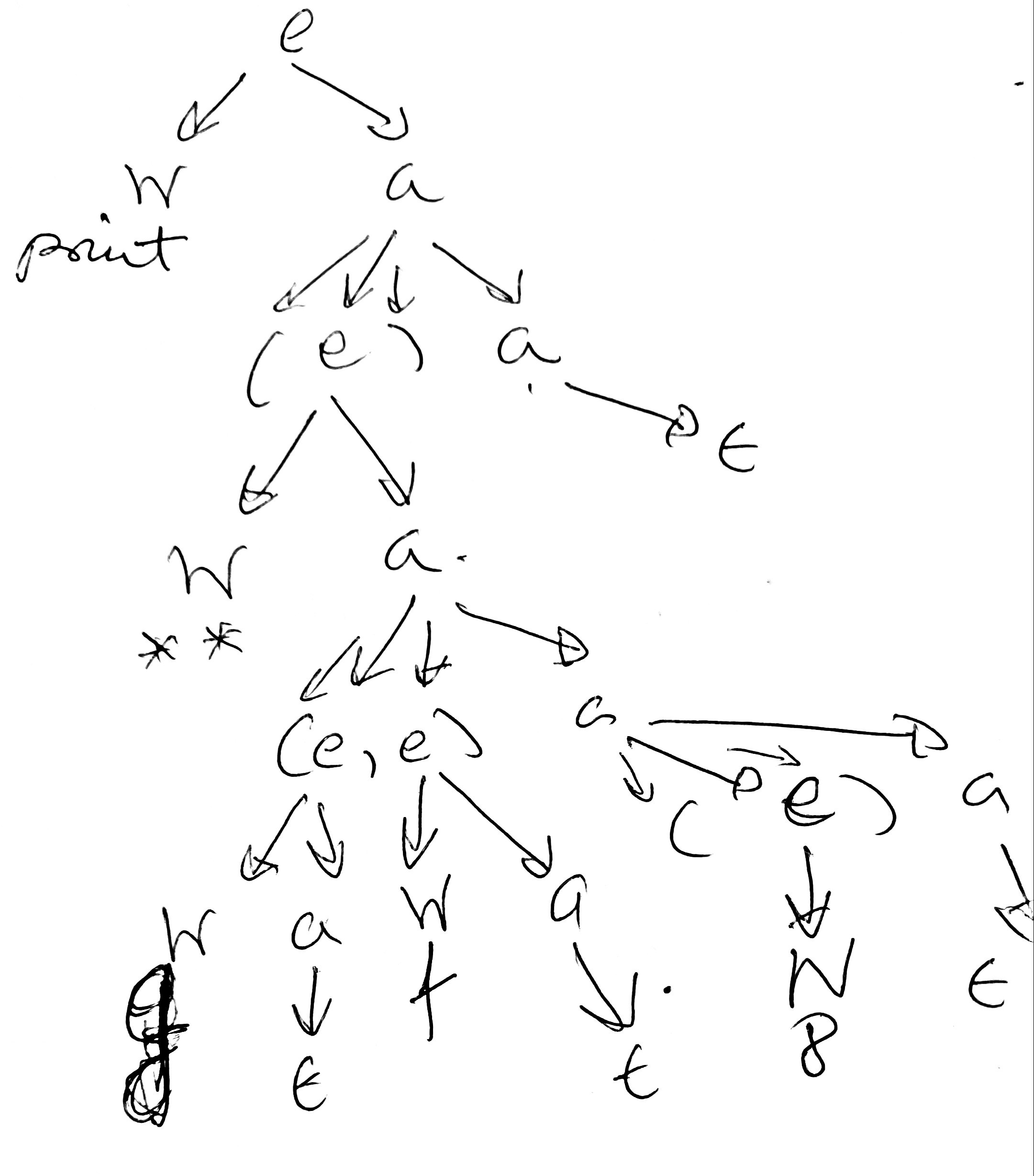
Construye una derivación para la frase
print(**(g,f)(8))
Observa que el resultado del análisis léxico sería un stream como este:
WORD["print"] "(" WORD[**] "(" WORD[g] "," WORD[f] ")" "(" NUMBER[8] ")" ")"
Solución:
En la solución que sigue, abreviamos expression por \(e\) , apply por \(a\), WORD por \(W\) y NUMBER por \(N\):
\(e \Longrightarrow W [print] a\) (Aquí \(e \longrightarrow W a\))
\(\Longrightarrow W[print] (e) a\) (Ya que \(a \longrightarrow (e) a\))
\(\Longrightarrow W [print] (e)\) (Ya que \(a \longrightarrow \epsilon\))
\(\Longrightarrow W[print] (W[**] a)\) (Aquí hizo \(e \longrightarrow W a\))
\(\Longrightarrow W[print] (W[**] (e, e) a )\) (Aquí hizo \(a \longrightarrow (e, e) a\))
\(\Longrightarrow W[print] (W[**] (e, e) (e) a )\) (La última a hizo \(a \longrightarrow (e) a\))
\(\Longrightarrow W[print] (W[**] (e, e) (e))\) (La última \(a\) hace \(\epsilon\))
\(\overset{*}{\Longrightarrow} W[print] (W[**] (W[g], W[f]) (N[8]))\) (después de aplicar reiteradas veces las reglas)
En forma gráfica, tenemos el árbol sintáctico concreto que sigue:
Este es el mismo diagrama hecho usando mermaid:
Lenguaje Generado por Una Gramática
Para cada variable sintáctica \(A \in V\) el lenguaje generado desde la variable \(A\) se define como:
\[L_A(G) = \{ x \in \Sigma^* : A \stackrel{*}{\Longrightarrow} x \}\]Esto es, \(L_A(G)\) es el conjunto de frases del alfabeto que derivan en varias substituciones desde la variable \(A\).
En los métodos de Análisis Sintáctico Descendente Recursivo (PDR) se asocia una subrutina con cada variable sintáctica \(A \in V\).
La función de dicha subrutina (que de ahora en adelante llamaremos parseA()) es reconocer \(L_A(G)\).
Siguiendo con el ejemplo de Egg, en \(L_{apply}(EggGrammar)\) tenemos frases como:
()(4,b)(4, +(5,c))(4,)/* nada */
Recuerda que:
apply: /* vacio */
| '(' (expression ',')* expression? ')' apply
y que:
\[L_{apply}(EggGrammar) = \{ x \in \Sigma^* : apply \stackrel{*}{\Longrightarrow} x \}\]Escribiremos una función parseApplyque se deberá encargar de reconocer las frases de \(L_{apply}(EggGrammar)\).
Por supuesto también escribiremos una función parseExpressionque se deberá encargar de reconocer las frases de \(L_{expression}(EggGrammar)\).
Una función por Variable Sintáctica
Repetimos: Cuando construimos un PDR
- Se escribe una rutina
parseApor cada variable sintáctica en la gramática \(A \in V\) - La función de
parseA()es reconocer las frases \(x \in L(A)\) en el lenguaje generado por \(A\) y construir el Arbol de Análisis de dichas frases \(x\).
La idea es bien simple: Si, por ejemplo \(A\) tiene una sola regla \(A \Rightarrow B \, C\)
entonces el código de parseA() sería tan simple como llamar primero a parseB()
y luego a parseC().
Por ejemplo, en Egg, para hacer el parser escribimos dos funciones
parseExpressionyparseApply.
La función parseExpression reconoce el lenguaje
y la función parseApply reconoce el lenguaje
El Token de Predicción
En un PDR, la estrategia general que sigue la rutina parseA para reconocer \(L(A)\) es
decidir en términos del terminal a por el que vamos en la entrada cual de las partes derechas \(\alpha_i\) de las reglas de \(A\)
se aplica para construir el árbol. Si es así, a continuación se pasa a comprobar que la entrada que sigue a continuación de a... pertenece al lenguaje generado por \(\alpha_i\).
Por ejemplo, en la gramática de Egg estas son las reglas para expression:
expression: STRING
| NUMBER
| WORD apply
Vemos que las tres reglas empiezan por un token distinto. Si sabemos que el token actual es STRING la regla para seguir será la primera y si es
WORD estamos seguros que la regla que se aplica es la tercera.
Calculando por donde empiezan las derivaciones
En un analizador predictivo descendente recursivo (PDR o APDR) se
asume que el terminal/token que actualmente esta siendo observado (que a partir de ahora denominaré lookahead) permite determinar unívocamente que producción de \(A\) hay
que aplicar.
Una vez que dentro del cuerpo de parseA se ha determinado que la regla concreta por la que
continuar la derivación es la regla \(A \rightarrow \alpha\), el algoritmo procede a reconocer
\(L_{\alpha}(G)\), el lenguaje generado por la parte derecha de la regla: \(\alpha\):
Para ello se procede así. Supongamos que \(\alpha = X_1 \ldots X_n\), donde \(X_i\) es o bien un token \(X_i \in \Sigma\) o bien una variable \(X_i \in V\).
-
las apariciones de terminales \(X_i\) en \(\alpha\) son emparejadas con los terminales en la entrada avanzando en el flujo de tokens,
lookahead = lex();
mientras que
- las apariciones de variables sintácticas \(X_i = B \in V\) en \(\alpha\) se traducen en llamadas a la correspondiente subrutina asociada con
parseB.
La secuencia de llamadas cuando se procesa la entrada mediante el siguiente programa construye “implícitamente” el árbol de análisis sintáctico concreto.
Los Conjuntos FIRST
El análisis predictivo confía en que, si
estamos ejecutando la entrada del procedimiento parseA, el cuál está
asociado con la variable \(A \in V\), el símbolo terminal a que esta en la
entrada determine de manera unívoca cual de las reglas de producción
\(A \rightarrow \alpha_i\) debe ser procesada.
Si se piensa, esta condición se puede satisfacer si se cumple que:
Para toda variable \(A\), las derivaciones de las partes derechas \(\alpha_i\) de sus reglas \(A \rightarrow \alpha_i\) “comienzan” por diferentes tokens.
Supongamos que \(\alpha \in (V \cup \Sigma)*\) es una frase de variables y terminales. Denotaremos por \(FIRST(\alpha)\) al conjunto de terminales que pueden aparecer al “comienzo” de una derivación desde \(\alpha\):
\[FIRST(\alpha) = \left \{ b \in \Sigma : \alpha \stackrel{*}{\Longrightarrow} b \beta \right \}\]Pseudocódigo de la Función de Parsing
Podemos reformular ahora nuestra afirmación anterior en estos términos:
Si
- \(A \rightarrow \gamma_1 \mid \ldots \mid \gamma_n\) son todas las reglas de producción de la variable \(A\) y
- los conjuntos \(FIRST(\gamma_i)\) son disjuntos,
entonces podemos construir la función
parseA para reconocer el lenguaje generado por la variable \(A\) siguiendo este seudocódigo:
function parseA() {
if (lookahead in FIRST(gamma_1)) { codigo gamma_1 }
else if (lookahead in FIRST(gamma_2)) { codigo gamma_2 }
...
else (lookahead in FIRST(gamma_n)) { codigo gamma_n }
}
Donde si \(\gamma_j\) es \(X_1 \ldots X_k\) el código gamma_j consiste en
una secuencia \(i = 1 \ldots k\) de uno de estos dos tipos de código:
-
Llamar a la subrutina
parseX_i()si \(X_i\) es una variable sintáctica -
Hacer una llamada al analizador léxico avanzando sobre el token
lex()si \(X_i\) es el terminal actual
Si aplicamos esta teoría a la variable sintáctica expression cuyas reglas eran:
expression: STRING
| NUMBER
| WORD apply
tenemos tres partes derechas \(\gamma_1\) = STRING, \(\gamma_2\) = NUMBER y \(\gamma_3\) = WORD apply. Si computamos los \(FIRST(\gamma_i)\) obtenemos:
FIRST(STRING) = { STRING }
FIRST(NUMBER) = { NUMBER }
FIRST(WORD apply) = { WORD }
nos produce este código:
function parseExpression() {
if (lookahead.type == "STRING") {
lex(); // Saltamos el token STRING
return;
} else if (lookahead.type == "NUMBER") {
lex(); // Saltemos el token NUMBER
return;
} else if (lookahead.type == "WORD") {
lex(); // Consumimos WORD
return parseApply(); // ... y llamamos a parseApply
} else {
throw new SyntaxError(`Unexpected syntax line ${lineno}: ${program.slice(0,10)}`);
}
}
Que hacer cuando aparecen reglas vacías
Aplicar el algoritmo PDR a las dos reglas de apply requiere añadir algunas extensiones al método.
Recordemos las reglas de apply:
apply: /* vacio */
| '(' (expression ',')* expression? ')' apply
Parece que si el lookaheades un '(' la regla que se aplica
es la segunda.
Mas difícil es determinar que tokens pueden aparecer cuando en la derivación se aplica la regla apply: /* vacio */.
Para poder responder a esta pregunta consideremos una derivación en la que intervenga la regla apply: /* vacio */
Si hacemos una derivación a derechas en la que esta es la última regla que se aplica, tendría que ocurrir algo como esto. Si derivamos desde el símbolo de arranque \(expression\):
\[expression \stackrel{*}{\Longrightarrow} \beta \, apply \, a_1\, a_2\, \ldots \, a_n\]en algún moomento en la parte derecha aparece apply quizá precedido de alguna secuencia \(\beta\), donde \(\beta\) es una cadena arbitraria de variables y terminales y los \(a_i \in \Sigma\) son terminales. Si derivamos por \(apply \longrightarrow \epsilon\) tenemos:
\[\Rightarrow \beta \, a_1 \ldots \, a_n\]Se sigue de la derivación anterior que cuando se aplica la regla apply: /* vacio */
cualquier token que, como es el caso del token \(a_1\), pueda aparecer en alguna derivación inmediatamente a continuación de apply
es un posible lookahead en la ejecución de parseApply().
Cálculo del FOLLOW
Tenemos entonces que computar el conjunto de tokens FOLLOW(apply) que pueden aparecer a continuación de la variableapply en alguna derivación desde expression.
\(FOLLOW(apply) = \left \{ a \in \Sigma : expression \stackrel{*}{\Longrightarrow} \beta \, apply \, a \, \alpha \right \}\) where \(\alpha \in (V \cup \Sigma)^*\)
Consideremos la siguiente sinopsis de derivación de una cadena como
print("hi", a)
en la que el símbolo \(\bullet\) denota el final de la cadena de entrada:
\[expression \bullet \Rightarrow WORD \, apply \bullet\]que deriva en:
\[\Longrightarrow WORD \, ( \,expression \, , \, expression \, ) \, apply \bullet\]que aplicando la regla \(apply \longrightarrow \epsilon\) deriva en:
\[\Longrightarrow WORD \, ( \,expression \, , \, expression \, ) \bullet\]Ya de aquí sacamos la conclusión de que el token final de la entrada está en los “follow” de apply:
\(\bullet \in FOLLOW(apply)\).
Así pues en el instante de la ejecución del análisis que se corresponde con ese punto de esta derivación se llamará a parseApply() y el valor de lookahead será el final de la entrada, que hemos denotado como \(\bullet\) (y que en nuestro analizador léxico se retorna como null).
Sigamos derivando:
\[\stackrel{*}{\Longrightarrow} WORD \, ( \,expression \, , \, WORD \, apply \, ) \bullet\]aplicando la regla \(expression \longrightarrow STRING\), tenemos:
\[\Longrightarrow WORD \, ( \, STRING \, , \, WORD \, apply \, ) \bullet\]que aplicando la regla \(apply \longrightarrow \epsilon\) deriva en:
\[\stackrel{*}{\Longrightarrow} WORD \, ( \, STRING \, , \, WORD) \bullet\]muestra claramente que el tokens es ')' está en los “follow” de apply:
\(')' \in FOLLOW(apply)\).
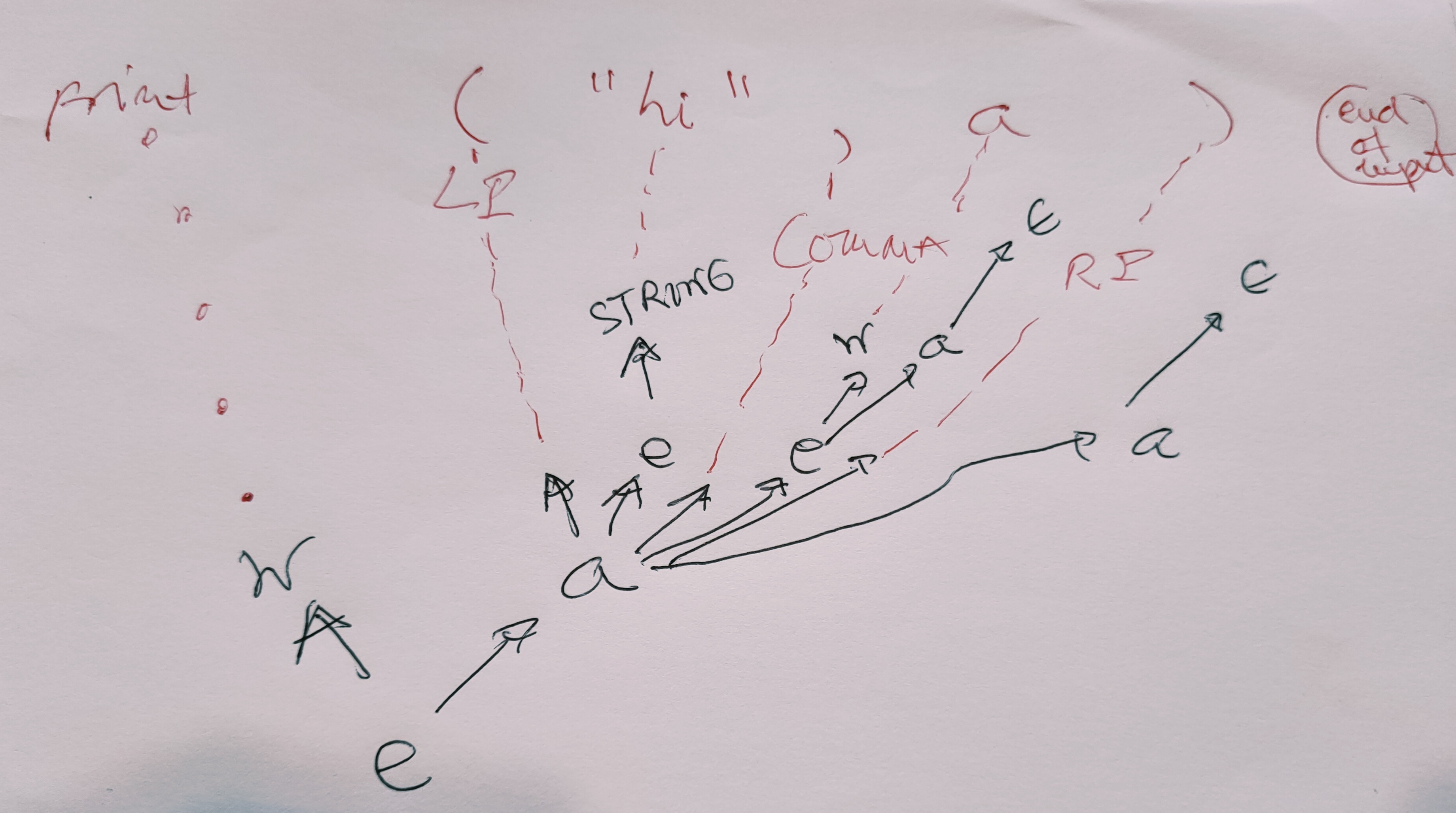
print("hi", a)
También si nos fijamos en esta otra derivación para una frase como 'x':
vemos de nuevo que apply aparece al final de la frase cuando se aplicó la regla de producción
\(apply \longrightarrow \epsilon\).
Así pues en el instante de la ejecución del análisis que se corresponde con ese punto de esta derivación se llamará a parseApply() y el valor de lookahead será el final de la entrada, que hemos denotado como \(\bullet\) (y que en el analizador léxico se retorna como null).
![]()
Asumiremos que el analizador léxico retorna un null cuando encuentra el final de la entrada.
Otro token que es fácil ver que puede seguir a apply es la coma. Se lo dejamos como Ejercicio: Busque una derivación en la que la coma aparezca siguiendo a apply
Por tanto el conjunto de los “follow” de apply son:
la coma “,” el fin de la entrada “\(\bullet\)” y el paréntesis cerrar”)”
Puesto que la segunda regla tiene un * indicando la repetición 0 o mas veces de la expresión entre paréntesis:
apply: '(' (expression ',')* expression? ')' apply
necesitaremos un bucle para ir procesando la expresión interior. El bucle se termina cuando vemos el paréntesis de cierre o bien si se produce el final de la entrada.
Entonces el código queda como sigue:
function parseApply() {
if (!lookahead) return; // token "End of Input": apply: /* vacio */
if ((lookahead.type === "RP")|| (lookahead.type === 'COMMA')) // apply: /* vacio */
return;
if (lookahead.type !== "LP") throw new SyntaxError(`Error: Found ${lookahead.type}, Expected ',' or '(' or ')'`);
lex(); // apply: '(' (expression ',')* expression? ')' apply
while (lookahead && lookahead.type !== "RP") {
parseExpression();
if (lookahead && lookahead.type == "COMMA") lex();
else if (!lookahead || lookahead.type !== "RP")
throw new SyntaxError(`Error`);
}
if (!lookahead) throw new SyntaxError(`Error`);
lex();
return parseApply();
}
Aunque esta versión controla mejor los errores, el código queda mas simple si seguimos
la estrategia de si el token lookahead es el paréntesis izquierdo
entonces se trata de la regla de producción del paréntesis y en caso
contrario es la regla \(apply \longrightarrow \epsilon\):
function parseApply(tree) {
if (!lookahead) return tree; // apply: /* vacio */
if (lookahead.type !== "LP") return tree; // apply: /* vacio */
lex();
tree = {type: 'apply', operator: tree, args: []};
while (lookahead && lookahead.type !== "RP") {
let arg = parseExpression();
tree.args.push(arg);
if (lookahead && lookahead.type == "COMMA") {
lex();
} else if (!lookahead || lookahead.type !== "RP") {
throw new SyntaxError(`Expected ',' or ')' at line ${lineno}: ... ${program.slice(0,20)}`);
}
}
if (!lookahead) throw new SyntaxError(`Expected ')' at line ${lineno}: ... ${program.slice(0,20)}`);
lex();
return parseApply(tree);
}